Yongkang Cheng
cyk1990422gmail.com
Hi! I'm currently a first-year PhD student in MLR Group, The MBZUAI. I'm working on Humanoid Interacting and Motion Generation, using multi-modal conditions such as speech, text scripts, keypoints and image. My works are priminaly focused on the avatars and humanoid robots. I received my M.E. from NWAFU, in 2024.6, and B.E. from NJAU, in 2021.6.
Prior to my PhD, I was a research scientist at Agibot X-Lab for Project LinkCraft (Core Contributor), and research intern Tencent AILab for motion generation.

Research interests
- Interacting Humanoid Robot
- Multi-Modal Generation for Motion
- Robot Agent
Selected Publications
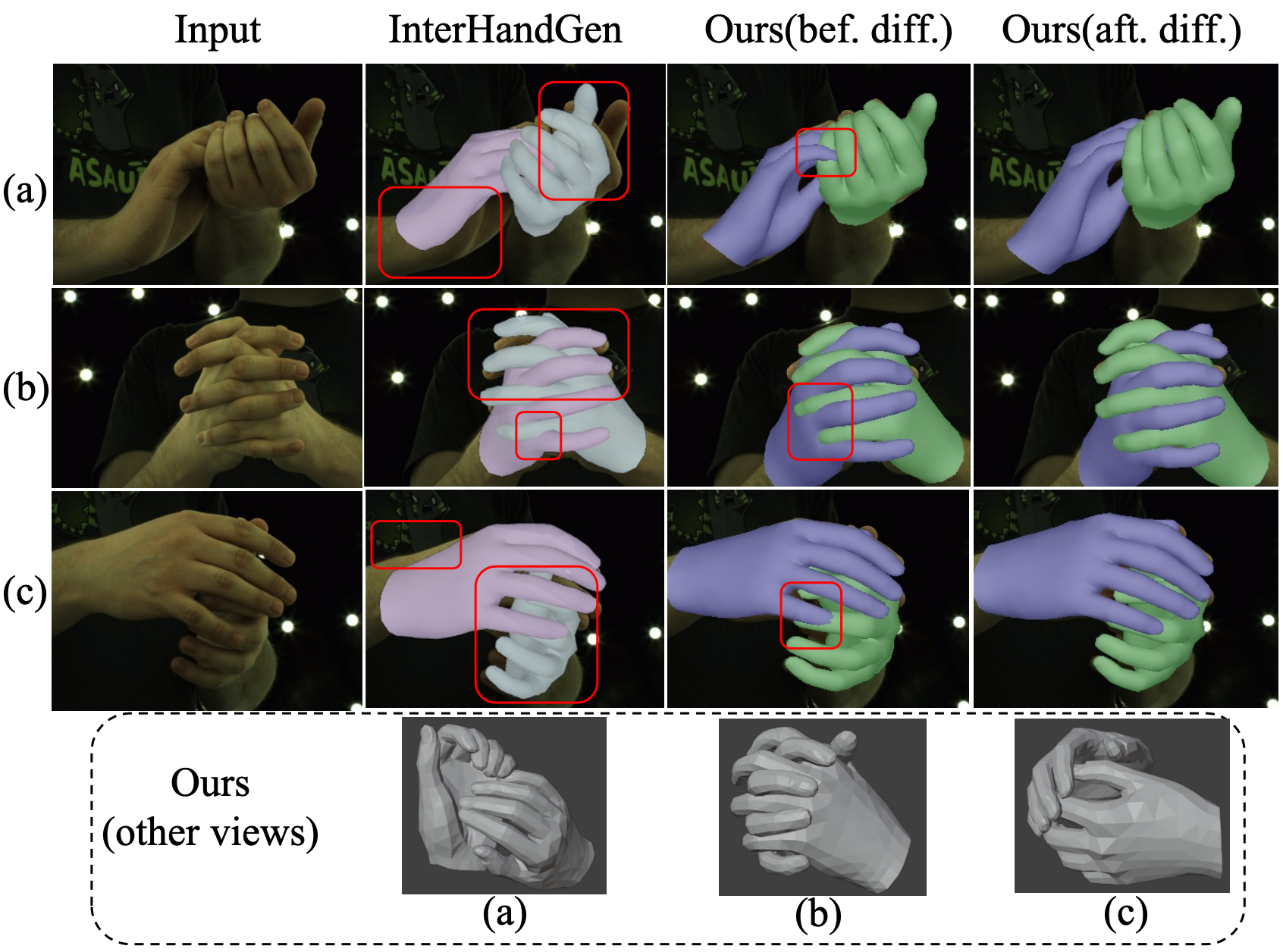
Aligning Foundation Model Priors and Diffusion-Based Hand Interactions for Occlusion-Resistant Two-Hand Reconstruction
Gaoge Han Yongkang Cheng Shaoli Huang† Zhe Chen Tongliang Liu
Computer Vision and Pattern Recognition, CVPR, 2026

ReBaR: Reference-Based Reasoning for Robust Pose Estimation from Monocular Images
Yongkang Cheng Mingjiang Liang Jifeng Ning Gaoge Han WeiLiu Shaoli Huang†
Pattern Recognition, 2026
Paper |
Project Page |

HoloGest: Decoupled Diffusion and Motion Priors for Generating Holisticly Expressive Co-speech Gestures
Yongkang Cheng Shaoli Huang†
International Conference on 3D Vision, 3DV, 2025
Paper |
Project Page |
Product

DIDiffGes: Decoupled Semi-Implicit Diffusion Models for Real-time Gesture Generation from Speech
Yongkang Cheng Shaoli Huang† Xuelin Chen Jifeng Ning Mingming Gong
The Association for the Advancement of Artificial Intelligence, AAAI, 2025
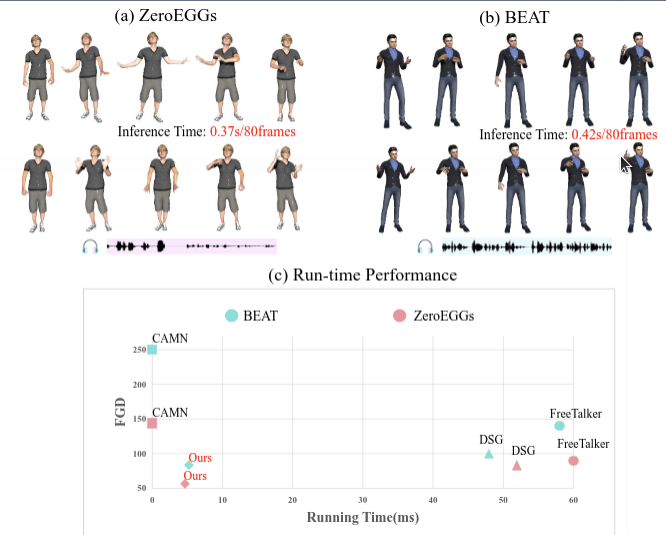
Conditional GAN for Enhancing Diffusion Models in Efficient and Authentic Global Gesture Generation from Audios
Yongkang Cheng Shaoli Huang† Jifeng Ning Gaoge Han WeiLiu
Winter Conference on Applications of Computer Vision, WACV, 2024

SignAvatars: A Large-scale 3D Sign Language Holistic Motion Dataset and Benchmark
Zhengdi Yu Shaoli Huang Yongkang Cheng Tolga Birdal
European Conference on Computer Vision, ECCV, 2024
Paper |
Code |
Project Page |
Video

ExpGest: Expressive Speaker Generation Using Diffusion Model and Hybrid Audio-Text Guidance
Yongkang Cheng Mingjiang Liang* Shaoli Huang† WeiLiu Jifeng Ning
International Conference on Multimedia and Expo, ICME, 2024
Experience
-
25.7 — Now 2025
 Agibot
– X-Lab
22.8 — 24.12 2022
Agibot
– X-Lab
22.8 — 24.12 2022 Tencent
– AILab
Tencent
– AILab
Academic Services
- Reviewer: CVPR, ECCV, ACMMM, WACV, ICME; IJCV, PR